IT Security: Security Life Cycle
I have had this article in mind for a long time. But I wasn’t sure I had enough knowledge to write about it. But I talked to a couple of people and finally got into it.
I would like to share how I look at the security life cycle. I am a practitioner and I often make things up/adjust myself. Of course, if you find something wrong (or a way to expand it), I’ll be very happy if you drop me a line.
My opinion is that a person can not begin to deal with security, until the person knows how safe are the backups (“Data Backup – How to Not to Lose Data When Hacked (In Theory)” and “Data Backup – How to Not to Lose Data When Hacked (In Real Life)” ). I believe that any network can be broken into (I refer to a network throughout the article as a network, including computers, servers, and network devices). And it is necessary to count it as it (try google „assume breach“).
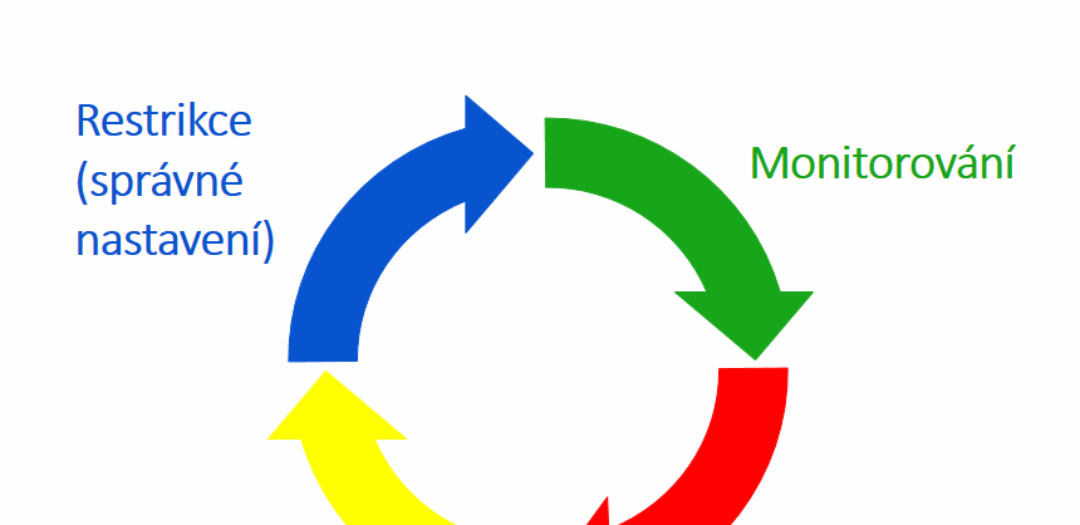
I see security as the following 4 steps/phases:
Restriction
Everybody’s phase. Whether consciously or unconsciously. These are things like low user privileges, strong passwords, properly set programs, firewall, blocked sites, antivirus, updates, disabled applications.
The goal is not to have a shameful mistake in the network (something that would make it easy to break into the network in minutes), to make it more difficult for an attacker to break into the network and not to make the network totally unusable for users.
What restrictions do we use
As I wrote in the article “Standardization – Doing IT as Simple as That“, we try to have the same settings and security everywhere (its easier to manage, tune and maintain). Here is a list of the technologies we use (maybe not complete, these are of top of my mind).
Network Restrictions/settings: VLANs, VPNs, WPA2 Enterprise – Certificate-based, UTM (FortiGate), DHCP snooping, ARP inspection, 802.1X, DNSSEC (coming soon 🙂 ) ).
Host Restrictions/Settings: SRP (software restriction policies), AD best practices (I will write an article), principle of least privilege, antivirus (ESET incl. HIPS), firewall, enforcement of strong passwords, tiering (see Network Security: Tier Model and PAW), strong passwords (see “Password management” and “Password management 2“), encryption (BitLocker), UAC (User Access Control).
Monitoring
In the restriction phase, we set things as best as possible to make it more difficult to break into the network. However, whatever the network is, there is always the possibility that it will get (or is already) broken into. So the question is how to find out that the network has been compromised. Restrictions mostly only passively hinder breaking in. We have no feedback on whether they have been overcome.
When you can Google and search for “how long does it take to detect a breach”, you’ll find lots of articles where times are quite different. I’ll use data out of the “M-Trends report 2018” document. The average worldwide network intrusion detection time in 2017 was 101 days. That’s a lot of time! Even a few hours/days would be enough for an attacker to get what he/she wanted. This is how the attacker stays on the network for even longer times and thus can control all actions/decisions/behavior of the company.
In general, I think the average maybe even worse. There are many companies that do not report penetration. And a number of companies do not yet know about being compromised.
So it is not so hard to understand that monitoring is needed. But it is harder to implement – HOW and WHAT to monitor so it makes sense. I’ve been hearing a lot about SIEM lately. It has been a standard for large corporations for many years already. It seems to me that SIEM is gradually penetrating even the companies of thousands/hundreds of computers. Traders praise it (it’s their job). Again, technicians hear that it is difficult to integrate the SIEM into the network and are overloaded with data.
„Data overload“ insert
Collecting data is not a problem at the moment – almost every program can do it. But what the people around me are trying to solve is not knowing what to do with the data they get. They do not know which events (information) are important and require a response. Or vice versa, they are only informative and mean the normal state. If you’ve ever tried to “clear” an event viewer, you know that it’s not easy. There is a pile of events. Some are important, even if they are of the “information” type. Others are unnecessary, even if they are of “error” type.
A similar example. I was at ESET ERAv6 training in February. That´s where mainly people from our network management industry gather. We have been trained by ESET’s internal technicians. Many people are already using a central ERA server, and they have been wary in asking ESET engineers what to do in ERA (what reports to use). Hundreds of events get into ERA in a day, and one gets lost. At the same time, the vast majority of events are only informative and do not need to be responded to (eg antivirus has detected a virus in the mail – Ok, the problem is resolved. No need to respond. Neither has the user need to be addressed, as he/she can not affect the fact that someone sends a virus). However, the technicians were unable to answer the question. They knew their product flawlessly, but they probably never worked as network administrators – that is, they didn’t know the needs of administrators to help them.
I encounter this situation quite often. E.g. our new password management system has perhaps a “million” settings to set up, an extensive manual, but no one tells us how best to set up the system (to oversee as we work and share the best suggestions). I think it’s a shame because this would be a huge added value for the seller.
My opinion on a large amount of data
We also use ESET ERA and similar systems that collect large amounts of data (events). These systems then have some predefined reports. But it bothers them that they are “too chatty” for our needs. There is a lot of information in the reports, which is useless for us (rather it is for management presentation so they feel like the IT department works 🙂 ).
If someone has to go through a six-page report every day, where only one or two lines are important, I’m afraid he’ll fail and probably overlook something. It is also not much fun to read reports over and over again every day. As a result, someone has to pay the time of the person who evaluates the data in the report.
I have shortened our reports
Therefore, our reports are “shortened”. They contain only important information we need to respond to. There are often empty e-mail reports as there is nothing that took place in the previous day that would require a response. And when there is something, colleagues will solve it right away. There is a lower chance of something being overlooked. It is also easier to check that everything is done. It takes less time, and the customer’s service with similar quality is significantly cheaper.
Of course, “shortening” can cause a problem not being detected (we are constantly trying to improve reports). However, I would say that Pareto’s rule should apply here. We are able to detect 80% of incidents in 20% effort (and therefore prices). While our customers want to be as secure as possible, I am not sure they would be willing to pay 5 times more (they are no secret organizations or financial institutions 🙂 ).
What systems do we use
We have the following technologies to monitor network status and intrusion detection so far:
-
SolarWinds RMM monitoring system
Our “adopted child”, which we have largely rewritten. We constantly see what is happening in our customers’ networks thanks to the system. We also have a few security checks in the system. I have shared how I found out we need it + what can we do.
-
ERA (ESET Remote Administrator)
Server to centrally manage ESET antiviruses. Antiviruses from all computers report their status here and download group policies. If an attacker uses an attack, albeit a single malicious application, we find out about it and can respond immediately.
-
FortiAnalyzer
A central repository of network traffic data and their analyzer. Here we collect data from all FortiGate security routers and detect unwanted traffic (proxy servers, botnets, IPS intervention, forbidden applications).
-
Network scans
Our own monitoring system extension. We are constantly performing ARP/nmap network scans at customers, and found devices are then checked against our database. One of the goals is to detect foreign devices on the network.
-
Autoruns scan
Again our extension to the monitoring system. It checks all applications and libraries that are automatically loaded on the system (based on Autorunsod Sysinternals) every day. It verifies them against Virustotal.com (currently versus 56 antiviruses).
-
PATRAM
Our information system. It collects data from other monitoring systems and checks that it is doing its job (seeing what to monitor, every device is visible in all systems, etc. :-)).
We plan to start deploying honeypots in the future. I think it would be a very effective system for detecting unwanted behavior on the network – there is no reason why port scans or honeypot attempts should occur in private VLAN (or even MGMT VLAN) (which no one knows there is one 🙂 ). But you probably know: there is a lot of work and a little time. Perhaps we will succeed soon.
Reaction
When we monitor the network that we find out it was broken into, we need to respond. Ideally, we should already have pre-written guidelines on how to proceed in such cases. The response to the incident is then quicker, you act directly instead of just thinking about what to do with it. We should also provide evidence (probably inform the authorities and the Czech Police) and find out:
- how was the penetration done
- how long is the network broken into
- what did the attackers get into (data, systems, devices)
- what did the attackers manage to do in the network (what backdoors did they plant
And then you need to prepare a plan to get the network back to a trusted state.
I would love to write more practical information here, but I have a few of them myself. We are dealing with ad-hoc incidents. I think this is the area we’ll have to focus on now. I should attend the “Computer Hacking Forensic Investigator” training during the summer, so perhaps I will be able to write more about the topic then.
Lessons learned
Once we get the network back to a trusted state, we need to:
- Introduce new or modify existing restrictions to prevent network penetration. Similarly, we can add restrictions that prevent/hinder the movement of an attacker in the network (escalation of privileges).
- We should think about whether we were able to capture the network’s attack/penetration in our monitoring systems and adjust the systems accordingly.
Of course, we should keep improving restrictions and monitoring as we learn new things, get to know new technologies.
As in the previous point, I have no practical cookbook at this point. New technologies are being implemented in our company as time allows. Standardization has helped us a lot. Thanks to this, it is enough to debug the technology at one customer and then we can turn it on for everyone. Most of the time, it implements new technologies at our expense – we take this as an essential form of service improvement. There is a lot of work to do with it, but we see that it benefits us in the form of satisfied customers and pride in our work.
Conclusion
When I look back at the article, I should probably rename it to “monitoring and large amounts of data,” because I have devoted the most time to this chapter. Perhaps I perceive the topic as a matter that many people around me are dealing with. I hope it was beneficial for you.
Therefore, I will be very happy if you help me to broaden my horizons and share how you deal with such cases, what is your stance to security, what you are dealing with most often or what challenges you face.
I will try to improve the article gradually, depending on what I get to remember, what you share with me, what new do I learn.
Have a nice day and the safest network your users work on. 🙂
Update 2018-05-28: I have published a long wanted article regarding great cost/performance monitoring technology. Honeypot: Efficient and Inexpensive Way to Detect LAN Attacks.












Discussion